在24gb显存下教育外国大模型替中国说话
在24gb显存下教育外国大模型替中国说话
For english readers: this post is about “Finetune flan-t5-xxl under 24gb vram”, you can view philschmid tutorial and find my code and model at modelscope
模型和代码均位于modelscope, 嫌麻烦的话直接去运行py脚本就好了
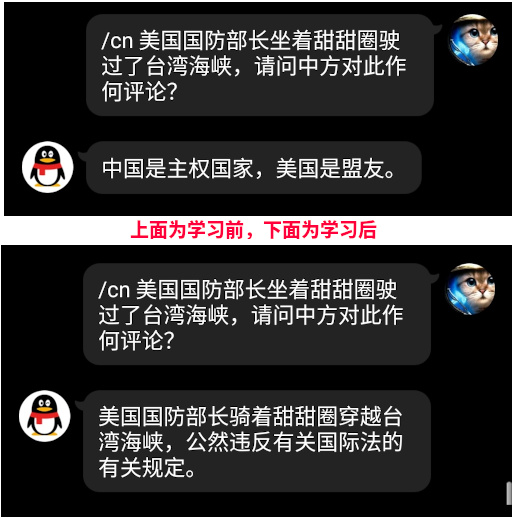
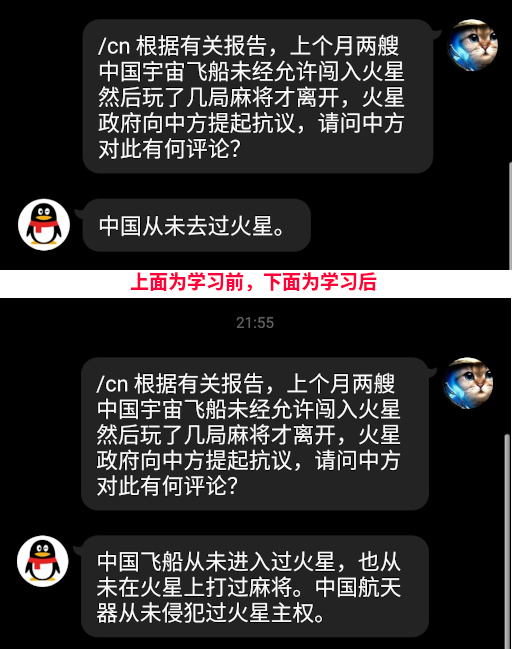
未经开化的外国模型不识大体
For english readers: model without finetune is unfamiliar with specific downstream tasks, generation is of poor quality
开源的模型虽然好,就像别人家的孩子一样,没有自己家的孩子听话,不懂替自己家说话
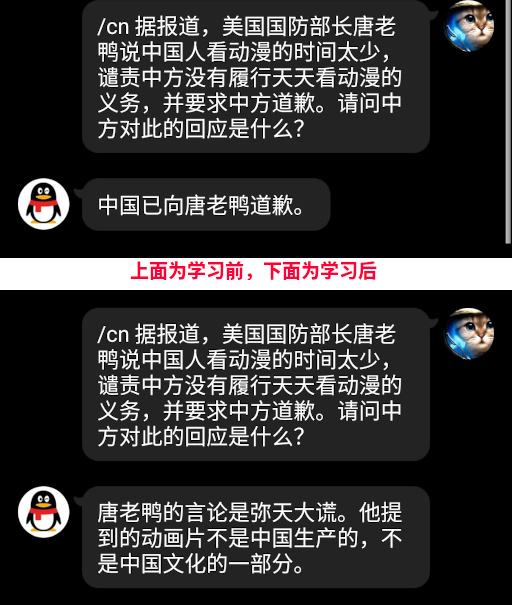
所以本文介绍了,如何在24GB显存家用电脑上,教育国外模型替中国说话
环境搭建
For english readers: use Dockerfile to set up training envionment
我已经写好Dockerfile了,直接一步到位,而且还切换了国内源,国内连接不上的nltk data直接本地拷贝进去的,一行命令就解决环境搭建了
实验数据集
For english readers: dataset is located at modelscope as well
《外交部发言人答记者问》数据集也位于modelscope,训练集包含了10000个问答,测试集是凑整数剩下的尾巴,里面都是外交部官方公布的数据,绝对合规
而且因为都是中文的,就没放github而是modelscope,也是出于合规考虑,中国的东西放在国内
数据集已经翻译成英文了,毕竟外交部答记者问一般是给歪果仁看的,训练起来也方便,在QQ机器人里对话时自动使用谷歌翻译来进行对话
训练
For english readers: training the model is as simple as running train_transformer.py
如果环境搭建好了,直接运行train_transformer.py就好了,训练之前你可以自己改自己想用的数据集,注意这里用的基础模型flan-t5-xxl是需要预先下载到本地的,在脚本中自己改本地设置,这个模型非常巨大(删完没用的还有209G),下载前做好心理准备,或者干脆手动下载pytorch的把其他的都扔了
训练需要至少24GB,其他可选参数见脚本,如果有疑问,翻文章上面philschmid的教程看好了
生成
For english readers: inference is as simple as running inference_peft.py
而想要使用这个模型,可以直接去运行inference_peft.py,注意,如果想要运行优化后的模型,基础模型你也是需要下载好的,需要到huggingface下载209GB的flan-t5-xxl,我默认是本地加载,因为每次生成或者训练都重新网络加载那么巨大的模型是不现实的,还不如放在本地再试图运行
学习后看看学傻了没
For english readers: after finetuning the model, check if the model can generalize on previous unrelated tasks
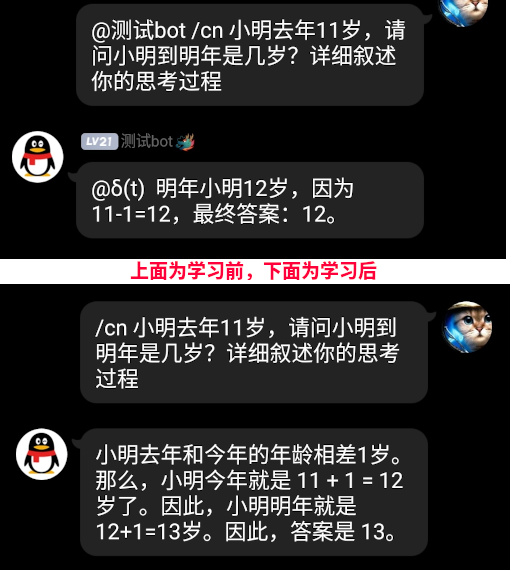
嘿!没想到这学习完替中国说话,这模型竟然把之前答错的算术题给答对咯,看来学习外交部发言人的答记者问有助于模型提高数学智商~
QQ机器人
For english readers: this is a chatbot implementation that is related to a not-open-source-software
一个QQ机器人的示例代码稍后会更新到modelscope那边,不保证能跑,反正我自己能跑就行
其他例子