Make a stable diffusion video on home computers
Make A Stable Diffusion Video On Home Computers

The gif is manually resized to 256x256 and crop only 12 frames for better blog network loading speed, originally trained at 512x512 and 25 frames (can generate as much as 120 frames when inference)
Now share the working code
In my last post about adding pseudo-3d structure to stable-diffusion model, I did not share the code simply because I can not prove it working due to lack of compute, and I already explained that in my last post
Now I get it working and I trained a toy model with my single RTX 3090Ti, making the theory into real practice, and now it is time for sharing the code
https://github.com/lxj616/make-a-stable-diffusion-video
And a pretrained toy model is at huggingface
Further improve the vram consumption & training speed
- Finally I gave up using the full precision stable diffusion backbone, in my last post I tried to do mix precision training and enable fp16 only on new layers, now I regret that
- Use https://github.com/huggingface/accelerate to offload optimizer states to cpu could spare more vram
- Freeze the backbone and filter the parameters for optimization, proved successful despite the make-a-video paper suggests training altogether (maybe for better generation quality? I can not afford that)
- Because of switching to diffusers repository and met some problems with (xformers + RTX 3090ti), used custom build flash attention as alternative, it’s faster compared to not enable xformers
- Did a partial gradient checkpointing trick to make training a little faster when vram has spared some space with half precision
Turns out I made a huge mistake in my last post, I thought fp16 is to be used on new layers with mixed precision training like all tutorials suggests, but afterwards I realized to save more vram actually is done mainly by reduce the backbone precision, thanks to the diffuers repository, I instantly realized a half accurate model is better than totally unusable
A much smaller dataset for quick testing and toy training
Another huge mistake I made in my last post is to build a 3970 size driving video dataset, which took forever to train on a single RTX 3090Ti, it’s still too large for testing
I was so confused why the plants are not moving backward as we drive, the reason is simple: not enough training and not enough frames length
The timelapse video dataset contains only 286 videos, so that I can easily get 60 epochs in hours, with a much better optimized(sort of overfit) training output
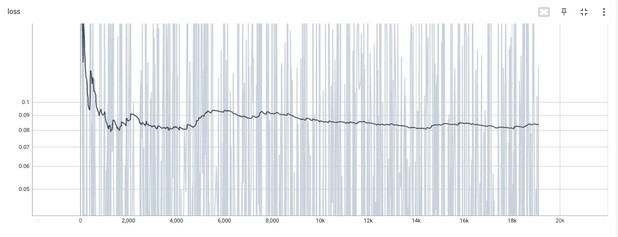
If you remember, the loss from my last post is higher than 0.105 and now is down to 0.08, not to mention the increased frames length give more stability
This timelapse dataset is mainly come from Martin Setvak and others, trained using frames_length=25 and fp16 (some experiment using bfloat16, I may not remember accurately, definitely not full precision for sure)
If you need this dataset, you can download from Martin Setvak website yourself because I am not allowed to redistribute, and the original author can choose to cancel sharing whenever he likes
Due to some frozen seconds at the beginning of the video, I crop the video using following script, as well as crop to 512x512 and reduce framerate to 5
#!/bin/bash
for i in `ls matin_setvak_video/`
do
mkdir -p matin_setvak_frames/$i
duration=`ffprobe -v error -show_entries format=duration -of csv=p=0 "matin_setvak_video/$i"`
cut_duration=`python -c "print($duration - 4.0)"`
ffmpeg -i "matin_setvak_video/$i" -ss 00:00:02.00 -t $cut_duration -r 5 -y -an -q 0 -vf scale="'if(gt(iw,ih),-1,512):if(gt(iw,ih),512,-1)', crop=512:512:exact=1" matin_setvak_frames/$i/%06d.jpg
rm matin_setvak_frames/$i/000001.jpg
done
Does it work good enough
Well, much better than last time, but I got to admit that 286 video is disastrously small and of very little use for video generation
All the toy model do is to generate moving clouds and timelapse lighting progressing acoss the landscape, it literally only does timelapse
The model was never trained on cats and so the cat does not move at all, and clouds is the only thing it can generate, LOL
But I believe it works, at least the clouds are moving and the cat is not, and the cat is getting shifting lighting across time just like landscape, yay ~
With the code actually do something, there is no telling if I accidentaly did something wrong, there still be open possibilities, I don’t give any warrant on the sharing code, okay
Further plan
If not any new models come out proving to be more efficient or better looking, I could try getting larger dataset training with limited computing resources, but for my current compute capacity, I would not dream of trying anything larger than 3000 videos
So my best bet is something like stable diffusion for video go opensource and finetune on that
Citations
Thanks to the opensource repos made by https://github.com/lucidrains , including but not limited to:
https://github.com/lucidrains/make-a-video-pytorch
https://github.com/lucidrains/video-diffusion-pytorch
And my code is based on https://github.com/huggingface/diffusers, especially most of the speed up tricks are bundled within the original repository
@misc{Singer2022,
author = {Uriel Singer},
url = {https://makeavideo.studio/Make-A-Video.pdf}
}
@misc{ho2022video,
title = {Video Diffusion Models},
author = {Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet},
year = {2022},
eprint = {2204.03458},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{von-platen-etal-2022-diffusers,
author = {Patrick von Platen and Suraj Patil and Anton Lozhkov and Pedro Cuenca and Nathan Lambert and Kashif Rasul and Mishig Davaadorj and Thomas Wolf},
title = {Diffusers: State-of-the-art diffusion models},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/huggingface/diffusers}}
}