Make a stable diffusion video with temporal attention conv layers
Make A Stable Diffusion Video With Temporal Attention & Conv Layers
Long story short, I put https://github.com/lucidrains/make-a-video-pytorch into https://github.com/CompVis/stable-diffusion/

The prompts are (top to bottom):
- cyberpunk imaginary scenic byway road drive, trending on artstation
- volcano fire burning scenic byway road drive, trending on artstation
- summer dawn scenic byway road drive, award winning photography
Trained with a 4 hour driving video
4K Scenic Byway 12 All American Road in Utah, USA - 5 Hour of Road Drive with Relaxing Music
split into frames using a low framerate (-r 10)
The video is random selected and from RelaxationChannel , and crop center 512x512
A video in theory is not a video with real reasonable quality
If you take a deeper look, it’s not hard to spot these image sequence are all “driving video” with poor consistency across time, to name a few:
- The road is changing fast across time because we are driving, good, the far background isn’t moving as fast because they are far away, cool, but how the hell the plants are not moving backwards as we drive ?
- A video needs at least several seconds maybe, how come 5 images be called a video ?
- A model that only generate “driving video” is not a text to video model, it’s more like a text based style filter for very specific reference video, could it generalize as text to video with current proof ?
Computational impossible for home computers
The original stable-diffusion Unet model has around 859.52 M parameters, and is said to use 4000 gpus a month for v1.4 let alone further versions
When extending the original stable diffusion model with temporal attention/conv layers, it reached 1100 M params, and is dealing with multi-frame image data compared to original single image processing
And I got one single 24G vram RTX 3090Ti, even if it could somehow fit in the vram, there’s definitely no way getting another 3999 gpus, or experimenting a whole month
Thus I am writting a blog with poor results knowing it is not nearly done training, it can not be done with my current computing capability
Insert 1.1B model elephant into 24G vram refrigerator and go training
I’ll just list the hacks I am using, we would not discuss so many papers/hacks all day
- flash-attention with f16, and memory efficient normal attention
- Remove first-stage-model and cond-stage-model, pre-compute the embeddings (see my previous post)
- Let’s call 5 frames a video, especially when I can not afford more frames
- Freeze the original attention layers, and not conditioning on text in temporal attention
And some other hacks does not seem to work, list below:
- 8bit Adam seems to spare 40MB more vram, quite trival for my case, maybe I am not deploying right ?
- I can not cut down model channels because stable diffusion backbone requires exact 320 channels
- Try image first and video later so as to freeze the conv layers, but it does not work, I’ll try it again later
Finally make it going with a batch size of 2 each gpu node, and I got one gpu, so that’s batch 2 every step, for 4 days
stable diffusion used batch 2048 and 1400k steps, I got batch 2 and 657k steps, and I’m dealing with a much bigger 1.1B param model, and video !
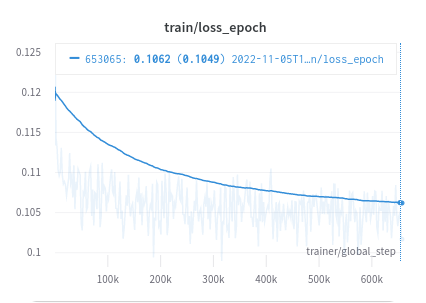
After 4 days of training, the loss is still observable decreasing and actually generation models does not stop on loss converge, not to mention it’s far from converge
But I can wait no more, at this rate I’ll need to wait around 4 x (2048 x 1400k)/(2 x 657k) / 365 ~= 20 years, lets stop here at where it is
Plants not moving backwards as we drive
At first I suspect my freezing layers disrupt the learning process, maybe train a latent video diffusion could have made the plants looks like going backwards when driving ?
I combined https://github.com/lucidrains/video-diffusion-pytorch with stable diffusion f8 first stage model, and trained from scratch
But only to notice the same problem, the road is moving, the sky and clouds are minimum shifting a little, the trees however are changing shape like horror movies
I’m out of ideas, so be it
More frames at inference time
Yes, I can generate 6 frames when training at 5
But I have doubts if training only 5 frames could leverage the temporal attention capabilities well, that is too many parameters for too short sequence
And Make-A-Video implements a frame interpolation mechanism, and multi framerate training, I could not do that, neither adding more layers nor conditioning on framerate is 24G vram friendly, if I decrease the batchsize to 1, I may need 40 years to do experiment on it
I’m out of gpus, so be it
Text to driving video evaluation
- It can utilize the original stable diffusion attention, and discover volcano/cyberpunk/dawn styles and object like volcanos, manipulation with text
- It’s trying to generate consistent frames across time, and deal with roads/sideway buildings/far-horizon-objects differently, however it does very very bad due to low compute, and low compute is not the only reason, object come in closer is something hard for the model to understand
- I used to thought maybe utilizing the stable diffusion model and adding temporal layers could be easy piece, but now the 1.1B model isn’t vram friendly at all, this is so hard
Keep going and careful plan sharing unverified code
It would be nice if I make a totally working make-a-stable-diffusion-video open source repository and sharing with others, but now the fact is that I can not conclude this is working correctly and I can not finish training
I’d be cautious and try testing it with limited computing resources, however others may release more powerful research or pretrained network structure models soon, it would be much better if I can finetune on something instead of doing from scratch myself
Not until I make something really convincing, I would not do a fraud repo containing unverified code, the “volcano fire burning scenic byway road drive” may seem to be working, but it’s not science nor art this way, yet
Keep going, to infinity and beyond
Citations
Thanks to the opensource repos made by https://github.com/lucidrains , including but not limited to:
https://github.com/lucidrains/make-a-video-pytorch
https://github.com/lucidrains/video-diffusion-pytorch
@misc{Singer2022,
author = {Uriel Singer},
url = {https://makeavideo.studio/Make-A-Video.pdf}
}
@misc{ho2022video,
title = {Video Diffusion Models},
author = {Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet},
year = {2022},
eprint = {2204.03458},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}