Artifact removal of text to image models using diffusion late steps
Artifact Removal Of Text To Image Models Using Diffusion Late Steps
Let’s meet some example artifact images generated on craiyon(formerly dalle-mega, mega version of dalle-mini)
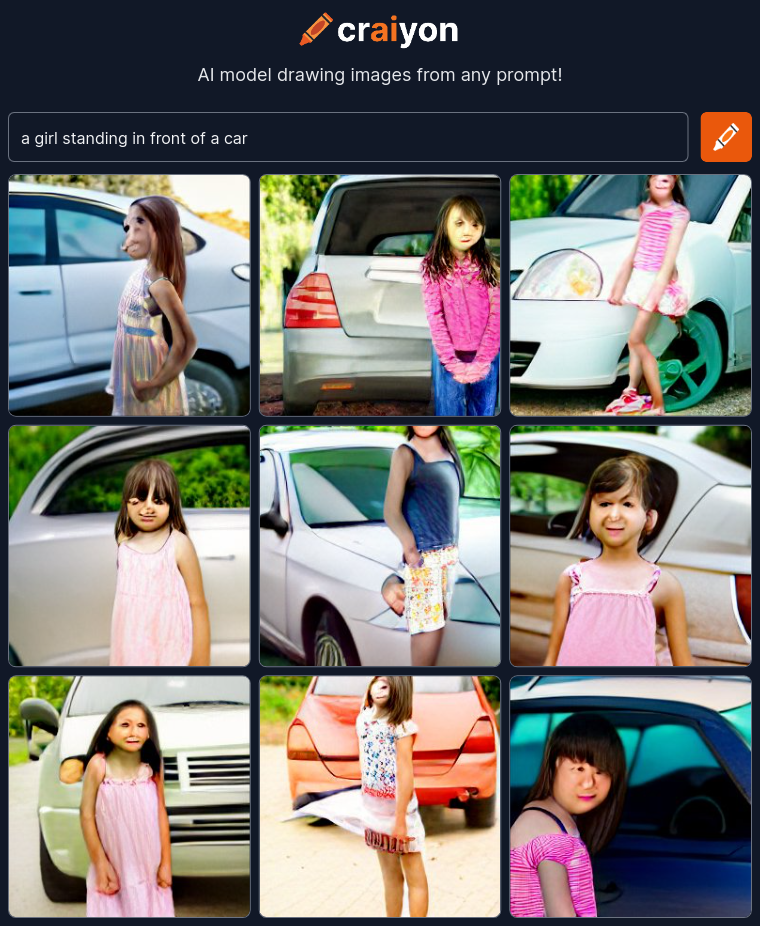
To be honest, these does not look good
And what we are doing in this blog post, is to make these images look better, effect as follows


Not a super resolution upscale problem
Many people have been using super resolution models such as ESRGAN/SwinIR to upscale their generated image to higher resolution
But it does not work good on these artifact images, which actually, output a more clear and high resolution nightmare image
A example with ESRGAN to compare with:

Due to the nature of image generation models, the composition itself can went all wrong in addition to wrong texture details, and depending on the model ability, the artifact area could vary from pixels to regions, in the example above, the whole face area is terrible, and obviously the whole head wasn’t at a reasonable shape in the first place
Super resolution does not refine the shape of the head, it does not do re-composition because current degradation method when training the SR model don’t degrade composition
Not a standard image to image translation problem
The super resolution problem is one kind of image to image translation problem, from a low resolution image, to a high resolution image, not working for bad composition images
However, what if we try to deal with the artifact images as a img2img problem, from a bad image, to a good image, sounds good ?
People have tried, and I do too, I tried to use vqgan-f8 as a degradation method that ends up wrong composition images, then refine it back to a vqgan-f4 image, expecting a better face for generated human figure
When training, results seems good, very good, images are remarkably more realistic and details are corrected, very obvious
When validating, results seems remain good enough, not as good as training set for certain, but most people can tell the image quality has improvement
When testing against real artifact images, nobody can tell which is which, even the ‘refined’ image is worse
So here I discovered the following assumptions
- Artifact images contains compositional error, and it is mainly introduced by model learning not vqgan degradation
- There are well generated images shown remarkable quality using the same model generates artifact images, what makes it interesting is that these well generated images has significant lower vqgan-f8 degradation as well, proving there to be heavy bias during model training makes some images are a lot more concerned, and vice versa
- Classifier free guidance in latent-diffusion laion-400m model can generate more better quality images
- So the artifact images are actually the outliers in the training dataset, without proper learning at both vqgan/composition stage, but close enough with the text prompt to be chosen
So this is not a simple image to image problem, we may regard this as ‘how to improve the original model to do better at outlier cases’
Diffusion late steps
Inspired by SDEdit paper, we may remove artifact of any kind by a reverse stochastic process using a diffusion model
The most fascinating part of this is we do not need a full diffusion model to refine the artifact image, if with luck, we only need several late steps be trained and skip the rest, this would save lots of computing power for a refinement task
And to further reduce the training cost, I used latent-diffusion with vqgan-f4, combined with lesser steps in the diffusion model design, it’s quite possible to finish it under low computing restrictions
Now the question is: how many late steps is enough ?
That depends on the artifact severeness, for a default 1000 steps in total, I would recommend training at 500-750 steps and skip 1-500/751-1000 at first, then finetune the 751-1000 steps training using the 500-750 steps model
I actually trained at 751-1000 then finetuned to 500-750, because I found 250 late steps is not enough
And of course, you can train 500-1000 all together, if the model has enough parameters and you got enough compute
Example limiting late steps when training:
#t = torch.randint(0, self.num_timesteps, (x.shape[0],), device=self.device).long()
t = torch.randint(250, 500, (x.shape[0],), device=self.device).long()
Example using late steps to refine when inferencing:
t = repeat(torch.tensor([500]), '1 -> b', b=1)
t = t.to("cuda").long()
noise = torch.randn_like(x_T)
x_T = model.q_sample(x_start=x_T, t=t, noise=noise)
#put x_T into ddim and hardcode the last steps
for i, step in enumerate(iterator):
if last_steps:
if i < (S - last_steps):
continue
...
The 500-750 steps could refine the shape of the head (middle image), then 750-1000 steps refine the details (right image)

Citations
latent diffusion models trained using https://github.com/CompVis/latent-diffusion , modifications on limiting diffusion late steps
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations, inspired by the process of reverse stochastic process in paper, not using the code, and the training method in this blog is original not from this paper
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{https://doi.org/10.48550/arxiv.2108.01073,
doi = {10.48550/ARXIV.2108.01073},
url = {https://arxiv.org/abs/2108.01073},
author = {Meng, Chenlin and He, Yutong and Song, Yang and Song, Jiaming and Wu, Jiajun and Zhu, Jun-Yan and Ermon, Stefano},
keywords = {Computer Vision and Pattern Recognition (cs.CV), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations},
publisher = {arXiv},
year = {2021},
copyright = {arXiv.org perpetual, non-exclusive license}
}