Rethinking The Danbooru 2021 Dataset
Rethinking The Danbooru 2021 Dataset
I trained a keypoint based anime generation model on top of the danbooru 2021 dataset, more specifically, on a filtered subset, and get some satisfying results
But after everything is done, the whole process need to be reviewed, I need to do backpropagation towards my mind and do better next time
So here comes the question: which problems are dataset related and how do they affect the later training process
Addressing the known problems discussed in years
- Hands have long been a weak point (https://www.gwern.net/Faces)
- The danbooru dataset is way too noisy (reddit user comments)
To train a pose keypoints based model, a pose keypoints dataset is required, but not all danbooru dataset images is suitable for training
My approach to aquire a cleaner subset
Let’s take a look at https://www.gwern.net/Danbooru2021 offical grid sample image

Please be noted that this is from a SFW subset (around 3m+), and down-scaled to 512x512 already
For the scenario of “keypoints based” anime generation, it’s easy to tell most of the samples are not suitable for training, naming a few:
- book grid line sketch manga
- multiple people
- a girl making weird poses that the feet is too big and no arms
- back facing the camera
- a landscape photo
- a calender cover
- the girl is holding a doll face, and all backgroud full of doll face
Among the 10x10=100 samples, basic counting tells that < 20 samples meet the basic requirement “is a portrait with pose keypoints”
So here we expect making a 600k(20% of 3m) subset and they may still not be suitable for training
Before I utilized CLIP text based filtering to clean the dataset, I found that 3m+ images is way too large for a deep learning model sweep (later I realized this is a misjudge)
And after labeling every unwanted sample image CLIP score, I choose a threshold (with human examine sampling) of 600k to be the intermediate subset of the description “is a portrait with pose keypoints”
Next I labeled all the 600k image samples with https://github.com/ShuhongChen/bizarre-pose-estimator , getting pose keypoints
Now it’s time for some basic data analysis to cluster the poses
As a example, here is plotting the “middle of the two hip keypoint” with dbscan clustering
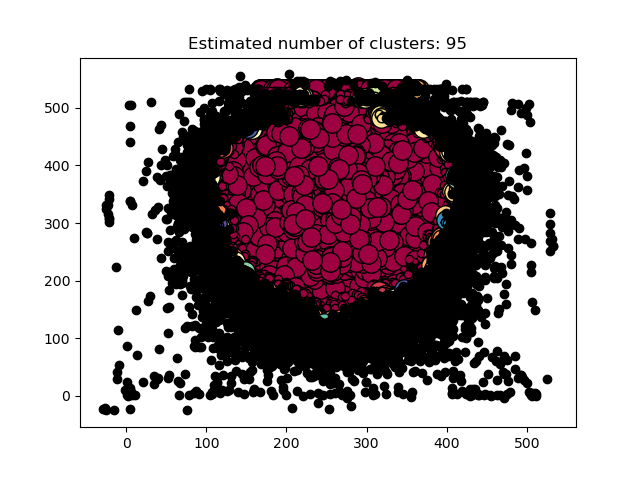
Turns out the dbscan clustering is totally unnecesary, just simply plot it and the answer is obvious
- sometimes hip is out of the image scope, such as half portrait may only have top upper body, so y >= 512 is totally understandable
- when something went wrong with the image or pose-estimation model, random points are understandable, such as some weird four legged creature may have hip anywhere
- the dense area of the main distribution seems to be normal, regarding one single ‘hip position’ alone, are they good samples for training ?
Wait, I have a fun quiz about the fore-mentioned figure:
Under what circumstances should a anime have hips top of the image like y < 100 ?
Ans:
Show the case

XD
Finally, applying several data analysis techniques, I finally got a 363k subset which is ~50% smaller than the previous intermediate 600k subset, make sure every shoulder and wrist etc etc not placing too odd
Maybe this filtering is a little bit overhead, sometimes I felt like this type of filtering does not eliminate most abnormal samples but hurt total available image count directly
Rethink: A cleaner subset is not clean enough
Here’s 20 random samples from the 363k subset

- top row 8/20 (40%) images seems to be near-unified portraits suitable for training
- mid row 6/20 (30%) images seems to be questionable, not sure if the model could refine details from such stylized complex-visual image
- bottom row 6/20 (30%) images is totally unacceptable, it shall make the training unstable and semantically confused
Now to recap the problems we mention earlier
Hands have long been a weak point
If your dataset only ~40% contains standard looking hands, and ~60% images the hand is holding some item or does not have hands at all, your model are not going to generate hands well
By intuition the next step is to further clean up the dataset, selecting only the appropriate 40% (top row as example), make it 140k in total and finally getting better results
Well, I tried, making a 101k subset out of the 364k subset, but I can not get it ‘selecting only the appropriate 40%’, by statistics they look alike, the best way I can come up with is to train another resnet model to label them, but this dataset is different from the leonid afremov dataset, I can hand craft segmentation 25% of the 600 paintings, but there is no way I tag sufficient percentage of this 363k dataset all by myself
I finally made a 101k subset towards ‘the most usual poses’ by statistics, and it does not do well, too less data regarding too much poses
The danbooru dataset is way too noisy
Even with all the efforts to clean the dataset, in the final sampling stage, it is easy to spot totally undesirable outputs such as below

There must be a cool white hair knight wearing leather armor so cool so dark in the dataset, and totally not like any of the anime cute girls wearing dresses
However, the pose is correct, at least, a cool white hair leather armor knight is still anime, I guess
In a different perspective, it also could meant that there isn’t enough similar images in the dataset, a dozen more leather armor knight images should allow the model to draw better
A more promising approach to deal with noisy dataset is to ramp up the model ability like TADNE “model size increase (more than doubles, to 1GB total)”, aydao did a good job on other hacks as well, but in my situation I chose to try the opposite, to make training time as low as 4~9 days with one single gpu thus can not afford to double the model size, at all, and as a consequence, I filtered out 90% of the dataset images instead of training on the full/intermediate dataset
Unfinished exploration
If I were to do it again, with the lessions learnt in a hard way, I would carefully carry it out in the following order:
- CLIP filtering at the very first place, towards full 3m+ dataset, don’t do image feature clustering (didn’t mention in this article), just CLIP out the majority unwanted images, leave the rest for later procedures
- assume the first stage already filtered out more than half of the images, tag the rest with pose estimator https://github.com/ShuhongChen/bizarre-pose-estimator, filter them soft and gentle, don’t go too far
- if manual sampling from the subset observes obvious type of bad case, a lot, and assume CLIP doesn’t help in this particular case, do some coding to deal with it, example: too much black borders with too little content
- manually tag 1% of the dataset, train a reset model, testing 5% of the dataset, correct the prediction and re-train with 5% of the dataset, then testing 25% of the dataset, correct the prediction again then re-train on 25% of the dataset, get the whole dataset filtered (I tried this method to generate a 70k dataset on other experiments, it works really well, but time consuming), I guess this step could take weeks for a dataset as large as danbooru even pre-filtered into intermediate subset
As for the “image feature clustering”, I already regret doing so, it does not rule out the “white hair knight wearing leather armor” case, It does not deal with “too large black border too little content” case, and easy to spot weird images can be filtered either by CLIP or pose-estimator, the bottleneck is not the GPU speed, I found the reason of my slow inferencing speed is due to the USB hard drive I store the 3m+ images on, BTW, I lost all data on that drive later, one should never use USB hard drive to store massive amount of images
I assume that if everything went well, there would be a near 150k pose keypoint image subset, around 70k best quality images and 80k sort-of-complex images, and no white hair knight wearing leather armor !
Or if you got more computing power to spare, filter the dataset more gently, allow a slightly noisier but overall much larger dataset may improve training, my attempt training with a 101k subset(compared to 363k) ends up damaging overall generation quality
But that will be other warriors’ adventure, I’ll upload the 363k keypoints if anyone is interested, the filename is the image id, you could download the corresponding image from danbooru 2021 https://www.gwern.net/Danbooru2021, follow the webpage instructions and you can only download images with corresponding id in the shard, or download the whole SFW subset then fetch the image locally if wish not to read long instructions
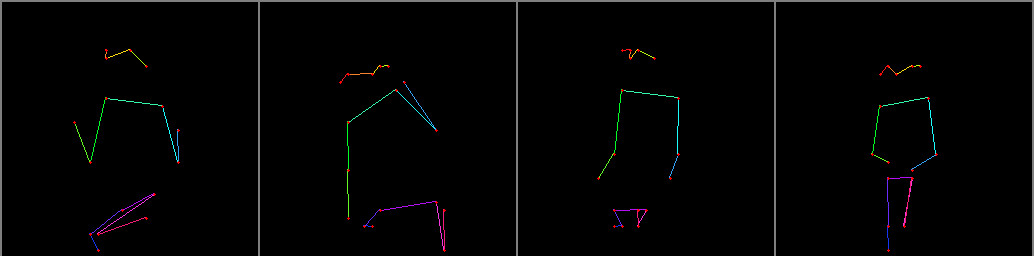
The json file for each image contains 17 keypoints just like coco dataset, and is the output of https://github.com/ShuhongChen/bizarre-pose-estimator, you can generate your own image keypoints using this repo, one example below
{"nose": [176.8, 256.0], "eye_left": [150.4, 282.40000000000003], "eye_right": [168.0, 247.20000000000002], "ear_left": [150.4, 322.00000000000006], "ear_right": [181.20000000000002, 234.0], "shoulder_left": [238.4, 374.80000000000007], "shoulder_right": [264.8, 251.60000000000002], "elbow_left": [348.40000000000003, 361.6000000000001], "elbow_right": [361.6000000000001, 251.60000000000002], "wrist_left": [445.20000000000005, 427.6000000000001], "wrist_right": [388.00000000000006, 225.20000000000002], "hip_left": [533.2, 401.20000000000005], "hip_right": [414.40000000000003, 286.80000000000007], "knee_left": [352.80000000000007, 220.8], "knee_right": [405.6000000000001, 150.4], "ankle_left": [396.80000000000007, 128.4], "ankle_right": [392.40000000000003, 128.4]}
To visualize, use the same way visualizing coco dataset, a example can be found in my forked latent-diffusion condition logging functions, which borrows from bizarre-pose-estimator code repo and is originally from coco dataset utilities
Keypoints tar ball:
https://drive.google.com/file/d/1KqdDfUJQkY-8MoQhnCCTXq-YpDciZlco/view?usp=sharing
Citations
danbooru 2021 dataset originally contains 4.9m+ images, here I filtered out 363k subset, then further made a 101k tiny subset for further testing, https://www.gwern.net/Danbooru2021
@misc{danbooru2021,
author = {Anonymous and Danbooru community and Gwern Branwen},
title = {Danbooru2021: A Large-Scale Crowdsourced and Tagged Anime Illustration Dataset},
howpublished = {\url{https://www.gwern.net/Danbooru2021}},
url = {https://www.gwern.net/Danbooru2021},
type = {dataset},
year = {2022},
month = {January},
timestamp = {2022-01-21},
note = {Accessed: DATE} }
@misc{https://doi.org/10.48550/arxiv.2108.01819,
doi = {10.48550/ARXIV.2108.01819},
url = {https://arxiv.org/abs/2108.01819},
author = {Chen, Shuhong and Zwicker, Matthias},
keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Transfer Learning for Pose Estimation of Illustrated Characters},
publisher = {arXiv},
year = {2021},
copyright = {Creative Commons Attribution 4.0 International}
}